Giving the increasing average price for license plates and decreasing success rate, I want to build a relatively accurate forecast model for average plate price. The key questions for this work include:
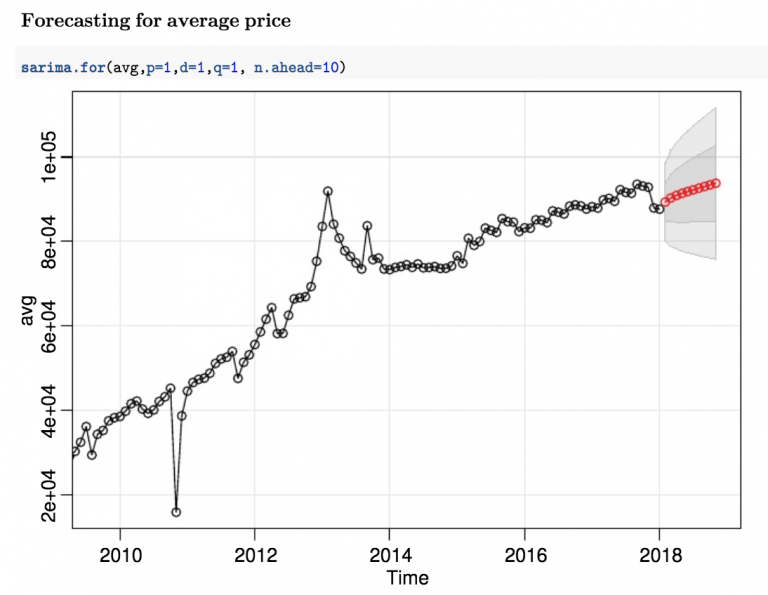
The average price of Shanghai license plate is well captured by a low order ARIMA model, namely a ARIMA(1,1,1). Comparing the forecast with the actual average price for March and April 2018, the model did a good job.
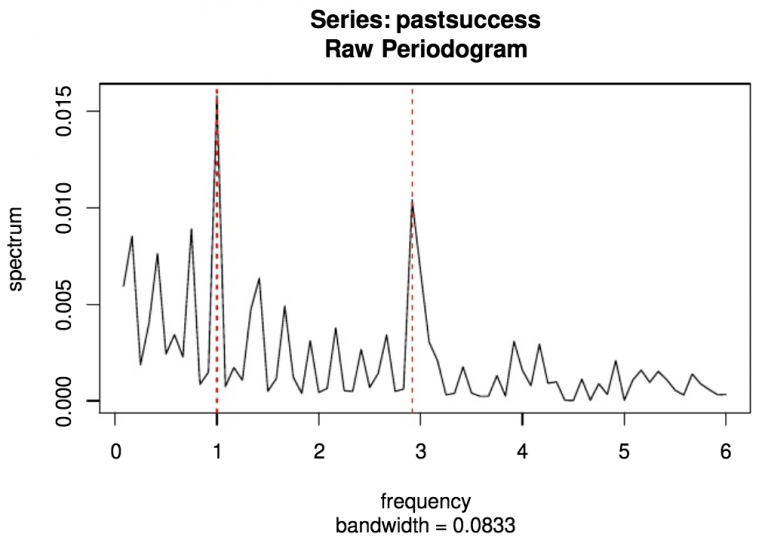
The successful application rate of Shanghai license plate is well captured by a low order seasonal ARMA model, namely a SARIMA(1,0,0)x(1,0,0)[12].
Forecasts predict the near term behavior of the series. The longterm forecasts converge to the estimated mean of the process, as expected. However, the seasonal model for successful application rate failed to see a sharp drop in 2014, which is caused by a sudden increase in the total number of applicants (the denominator for the success rate).
The reason for the increasing applicants is unclear, but we need to be mindful about the impact of future events (or people’s expectations) instead of just focusing on the past data when we build model.
You can read the full report (with my code and graphs) here
I built three models. The first models is a logistic regression model with all variables. After checking the multi-collinearity, I built the second model using all the variables except loudness, and the third model using all the variables except energy.
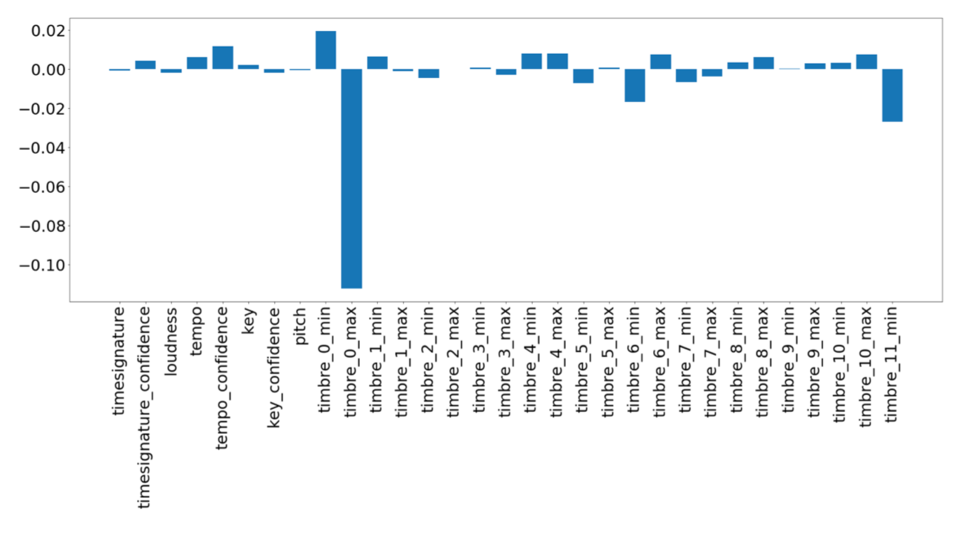
Model 3 had the best performance by predicting 287 Not Top10 songs and 29 Top10 songs correctly using a threshold of 0.45. Furthermore, by plotting the coefficient significance, we found the top 2 predictors for record success are timbre_0_max and timbre_11_min, while coefficients of variables such as loudness and energy are close to 0, meaning that heavy instrumentation is not a significant factor in the mainstream taste.